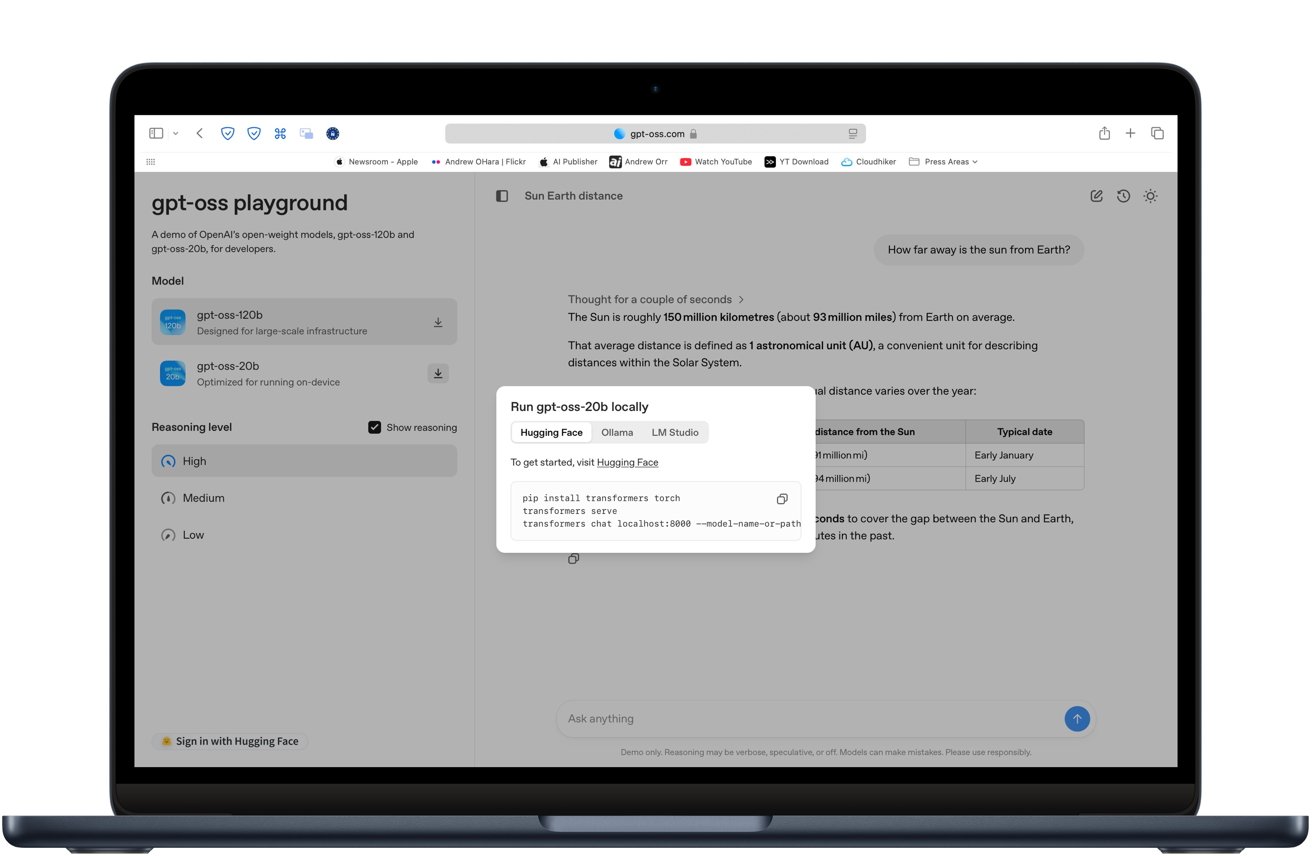
OpenAI’s newest gpt-oss-20b model lets your Mac run ChatGPT-style AI with no subscription, no internet, and no strings attached. Here’s how to get started.
On August 5 OpenAI released its first open-weight large language models in years, allowing Mac users to run ChatGPT-style tools offline. With the right setup, many Apple Silicon Macs can now handle advanced AI processing without a subscription or internet connection.
Running a powerful AI model on a Mac once required paying for a cloud service or navigating complex server software. The new gpt-oss-20b and gpt-oss-120b models change that.
The models offer downloadable weights that work with popular local-AI tools like LM Studio and Ollama.
You can try the model in your browser before downloading anything by visiting gpt-oss.com. The site offers a free demo of each model so you can see how it handles writing, coding, and general questions.
What you need to run it
We recommend at least an M2 chip, and 16GB of RAM. More is better. If you have an M1 processor, we recommend the Max or Ultra. A Mac Studio is an excellent choice for this, because of the extra cooling.
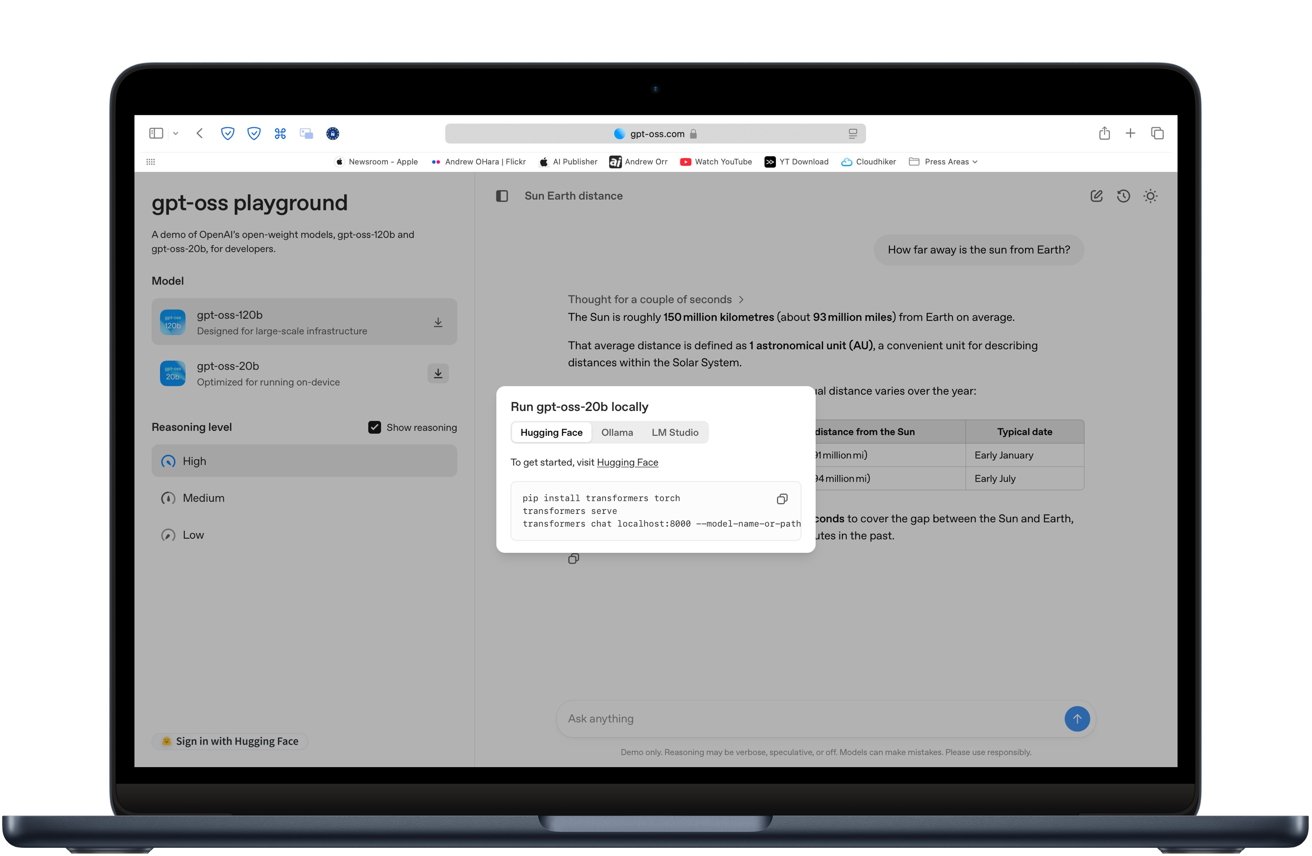
You can try the model in your browser before downloading
The model struggled a bit on our MacBook Air with an M3 chip. As you’d expect, it heated up too.
Think of it like gaming on the Mac. You can do it, but it can be demanding.
To get started, you’ll need one of these tools:
- LM Studio — a free app with a visual interface
- Ollama — a command-line tool with model management
- MLX — Apple’s machine learning framework, used by both apps for acceleration
These apps handle model downloads, setup, and compatibility checks.
Using Ollama
Ollama is a lightweight tool that lets you run local AI models from the command line with minimal setup.
- Install Ollama by following the instructions at ollama.com.
- Open Terminal and run
ollama run gpt-oss-20bto download and launch the model. - Ollama will handle the setup, including downloading the right quantized version.
- Once it finishes loading, you’ll see a prompt where you can start chatting right away.
It works just like ChatGPT, but everything runs on your Mac without needing an internet connection. In our test, the download was about 12 GB, so your Wi-Fi speed will determine how long that step takes.
On a MacBook Air with an M3 chip and 16 GB of RAM, the model ran, but responses to questions took noticeably longer than GPT-4o in the cloud. That said, the answers arrived without any internet connection.
Performance & limitations
The 20-billion-parameter model is already compressed into 4-bit format. That allows the model to run smoothly on Macs with 16 GB of RAM for various tasks.
- Writing and summarizing text
- Answering questions
- Generating and debugging code
- Structured function calling
It’s slower than cloud-based GPT-4o for complex tasks but responsive enough for most personal and development work. The larger 120b model requires 60 to 80 GB of memory, making it practical only for high-end workstations or research environments.
Why run AI locally?
Local inference keeps your data private, since nothing leaves your device. It also avoids ongoing API or subscription fees and reduces latency by removing the need for network calls.
Because the models are released under the Apache 2.0 license, you can fine-tune them for custom workflows. That flexibility lets you shape the AI’s behavior for specialized projects.
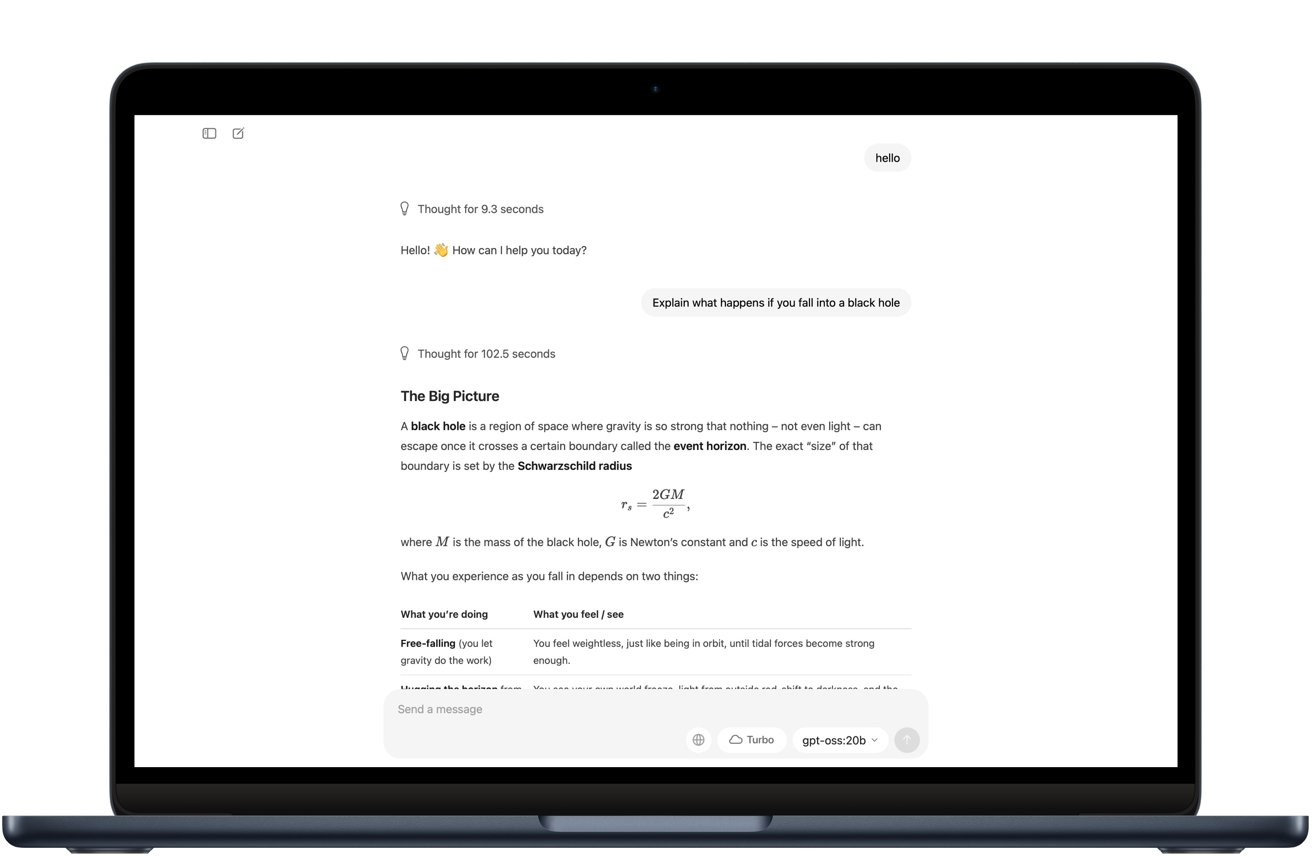
There are some limitations to the model
Gpt-oss-20b is a solid choice if you need an AI model that runs entirely on your Mac without an internet connection. It’s private, free to use, and dependable once it’s set up. The tradeoff is speed and polish.
In testing, it took longer to respond than GPT-4 and sometimes needed a little cleanup on complex answers. For casual writing, basic coding, and research, it works fine.
If staying offline matters more to you than performance, gpt-oss-20b is one of the best options you can run today. For fast, highly accurate results, a cloud-based model is still the better fit.
Tips for the best experience
Use a quantized version of the model to reduce precision from 16-bit floating point to 8-bit or 4-bit integers. Quantizing the model means lowering its precision from 16-bit floating point to 8-bit or about 4-bit integers.
That cuts memory use dramatically while keeping accuracy close to the original. OpenAI’s gpt-oss models use a 4-bit format called MXFP4, which lets the 20b model run on Macs with around 16 GB of RAM.
If your Mac has less than 16 GB of RAM, stick to smaller models in the 3 to 7 billion parameter range. Close memory-intensive apps before starting a session, and enable MLX or Metal acceleration when available for better performance.
With the right setup, your Mac can run AI models offline without subscriptions or internet, keeping your data secure. It won’t replace high-end cloud models for every task, but it’s a capable offline tool when privacy and control are important.