Chatbots are everywhere. They’re fashionable, easy to build, and even easier to demo. With powerful open-source libraries and APIs, you can spin up something that looks impressive in minutes. But while a prototype is enough to wow a colleague or investor, it’s not the same as a production-ready AI assistant that real users can rely on.
This article explores the journey from the simplest chatbot to a robust, scalable assistant — highlighting both the pitfalls and the critical steps along the way.
Starting Simple: The Minimal Chatbot
The most stripped-down chatbot is little more than an API wrapper. A user sends a message, the system records it in a list, and the model generates a reply. Tools like FastAPI and the OpenAI API make this trivial to implement.
from fastapi import FastAPI
from pydantic import BaseModel
from openai import OpenAI
OPENAI_API_KEY = "YOUR_API_KEY_HERE"
app = FastAPI()
client = OpenAI(api_key=OPENAI_API_KEY)
conversation = [
{"role": "developer", "content": "You are a helpful assistant."}
]
class Message(BaseModel):
content: str
@app.post("/chat")
def chat(message: Message):
conversation.append({"role": "user", "content": message.content})
completion = client.chat.completions.create(
model="gpt-4.1",
messages=conversation
)
reply = completion.choices[0].message.content
conversation.append({"role": "assistant", "content": reply})
return {"response": reply}
If even that feels too verbose, frameworks like LangChain (or its lightweight cousin LangGraph) abstract away the plumbing, letting you spin up conversational agents with just a few lines of code.
import langgraph
from fastapi import FastAPI
from pydantic import BaseModel
OPENAI_API_KEY = "YOUR_API_KEY_HERE"
app = FastAPI()
client = langgraph.Client(api_key=OPENAI_API_KEY)
conversation = client.conversation(system_prompt="You are a helpful assistant.")
class Message(BaseModel):
content: str
@app.post("/chat")
def chat(message: Message):
conversation.add_user(message.content)
reply = conversation.generate()
return {"response": reply}
The library offers excellent extensibility. Want to add retrieval-augmented generation (RAG) with an in-memory vector store? Here’s how:
from fastapi import FastAPI
from pydantic import BaseModel
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
OPENAI_API_KEY = "YOUR_API_KEY_HERE"
app = FastAPI()
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
vectorstore = FAISS.load_local("faiss_index", embeddings)
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(openai_api_key=OPENAI_API_KEY, model="gpt-4"),
retriever=vectorstore.as_retriever(search_kwargs={"k": 3})
)
chat_history = []
class Message(BaseModel):
content: str
@app.post("/chat")
def chat(message: Message):
result = qa({"question": message.content, "chat_history": chat_history})
chat_history.append((message.content, result["answer"]))
return {"response": result["answer"]}
Adding Observability
I assume you want to observe all conversations with your chatbot. Langfuse exists for that purpose and the integration is of course a part of LangChain.
from langfuse.langchain import CallbackHandler
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
langfuse_handler = CallbackHandler()
llm = ChatOpenAI(model_name="gpt-4o")
prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
chain = prompt | llm
response = chain.invoke({"topic": "cats"}, config={"callbacks": [langfuse_handler]})
print(response.content)
Want to measure response quality? RAGAS has you covered, with results displayed directly in your Langfuse dashboard:
metrics = [
Faithfulness(),
ResponseRelevancy(),
LLMContextPrecisionWithoutReference(),
]
async def score_with_ragas(query, chunks, answer):
scores = {}
for m in metrics:
sample = SingleTurnSample(
user_input=query,
retrieved_contexts=chunks,
response=answer,
)
print(f"calculating {m.name}")
scores[m.name] = await m.single_turn_ascore(sample)
return scores
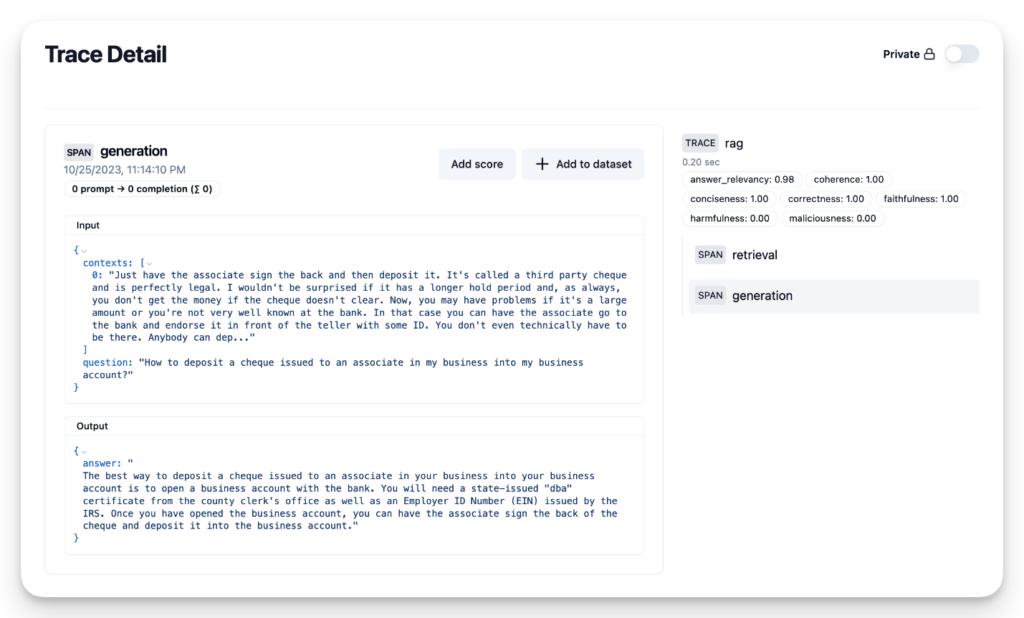
question = row['question']
trace = langfuse.trace(name = "rag")
contexts = row['contexts']
trace.span(
name = "retrieval", input={'question': question}, output={'contexts': contexts}
)
answer = row['answer']
trace.span(
name = "generation", input={'question': question, 'contexts': contexts}, output={'answer': answer}
)
ragas_scores = await score_with_ragas(question, contexts, answer)
for m in metrics:
trace.score(name=m.name, value=ragas_scores[m.name])
Voilà! Your chatbot now features sophisticated monitoring with RAGAS scores:
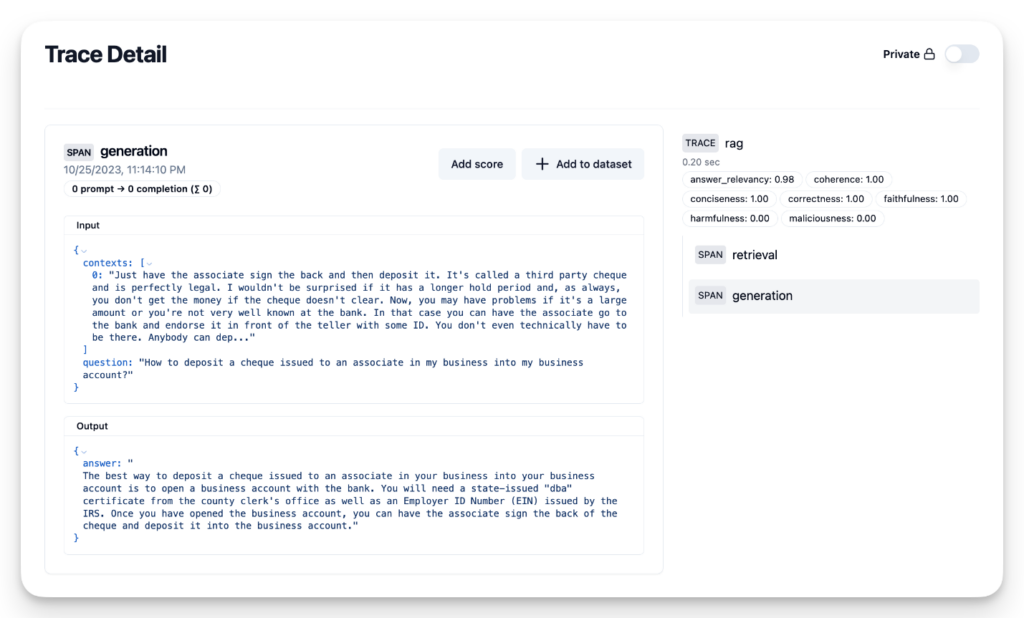
Source: https://langfuse.com/guides/cookbook/evaluation_of_rag_with_ragas
The result works — technically. But let’s be clear: at this stage, what you have is a chatbot. A proof of concept. Not yet a real assistant.
Beyond the Prototype: Critical Gaps
Here’s a simplified flow of your current implementation:
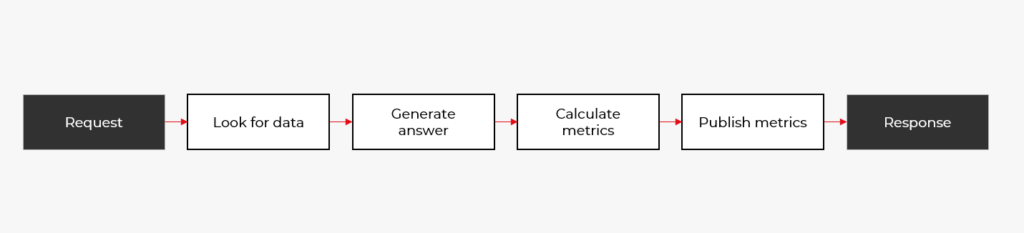
So why isn’t this enough? Because the prototype omits fundamental capabilities that make the difference between a toy project and a reliable product. Let’s look at the essential areas you’ll need to address.
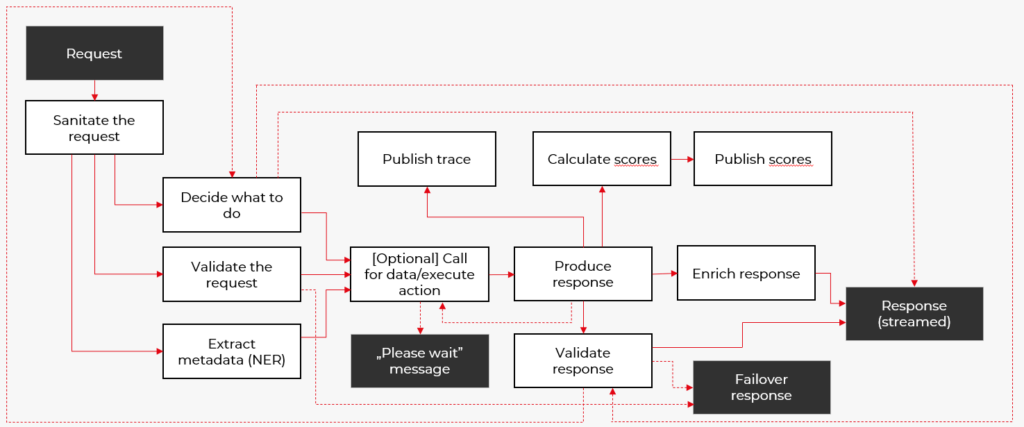
Asynchronous Communication
The glaring omission in the basic architecture is represented by those dark boxes on the bottom-right corner – the outbound messages. A classic synchronous request-response pattern is poorly suited for AI assistants. Generating an answer can take 10–20 seconds, which feels like an eternity. Instead, you can implement streaming with Server-Sent Events (SSE) or WebSockets, so users will see partial responses within a few seconds. Additionally, you can push helpful “still working” updates when needed. Just decide do you want to do that based on waiting time or maybe the number of tools called.
Speaking of tools…
Tool Orchestration
Our prototype blindly searches for data on every utterance — even a simple “hi!” triggers a vector similarity lookup. That’s wasteful. Better to treat the LLM as an orchestrator: send it the available tools (data sources, API calls, operations) and let it decide, “For this prompt I need to query source X” or “I should perform operation Y to resolve the issue.” That is the “decide what to do” phase. Your app then executes the plan — fetch data, call an external API, etc. You can handcraft each operation or lean on the Model Context Protocol (MCP) and its server of prebuilt capabilities. At this point you’ll want to swap out the in-memory store for a real vector database such as ContextClue or Qdrant.
Once you have the tool’s output, feed it back to the LLM, which can then decide whether to invoke another tool or craft the final answer.
Please note that this step is optional – the LLM always decide to call or not to call tools and it can just produce a simple response without employing extra steps.
- User: Hi! [you have tools X and Y available]
- Assistant to the user: Hi, how can I help you? (no tool is executed)
- User: I can’t connect to the Internet [you have tools X and Y available]
- Assistant internally: [call X for more details]
- X internally: [answer]
- Assistant internally: [call Y with parameters “a” and “b” to fix it]
- Y internally: [answer]
- Assistant to the user: I’ve found the problem and fixed it! Please try again
Input Sanitization and Request/Response verification
Then there’s the sanitization layer. You typically want to scrub the user’s input — strip personal data and remove obvious prompt‑injection attempts. You can employ a small LLM for this or rely on old‑school pattern matching. Libraries like Microsoft Presidio or OpaquePrompts can help, and resources like the LLM Prompt Injection Prevention guide provide valuable insights. Also there are more sophisticated solutions like Guardrails AI or Nvidia NeMo. On the other hand, often a custom verifier prompt is sufficient. This also lets you maintain a whitelist of allowed topics, dramatically improving safety by steering the conversation away from problematic scenarios.
Output validation comes with a tradeoff: safety versus speed. In the safe approach you wait for the whole answer and then validate it — at the cost of extra latency. Alternatively you can start streaming and validate either at the end or periodically (say every 100 tokens). Users get responses sooner, but in rare cases you might need to swap the partial answer for a pre-defined placeholder (see example).
Parallel Processing
Validation isn’t the only thing you can parallelize. Let’s distinguish 3 groups of tasks to run concurrently:
- Input processing
- Request validation for safety with whitelist check
- First LLM call
- Metadata extraction
- Tools execution
- Response processing
- Response validation
- Response enrichment
Tracing and scoring also deserve their own threads. Langfuse calls are usually quick, but RAGAS is notoriously sluggish, invoking multiple LLM calls and in memory models to compute its metrics. There’s no reason to hold up the user while those statistics churn.
That brings us to the elephant in the room — Python.
The Python Problem
The uncomfortable truth about Python in production AI systems is all AI libraries are made for Python first, but Python is not designed to work in AI systems.
In an LLM application most of the wall‑clock time is spent waiting – for the model, for data, for an MCP calls. In Python, you’re limited by Global Interpreter Lock (GIL), and you must manually start as many workers as available for your CPU to utilize your resources.
Consider this challenge – RAGAS isn’t thread safe. Though it uses asyncio under the hood, it may spin up multiple waiting threads and saturate your CPU even for a single trace. You might not notice it during running a demo for your stakeholders, but even small stress tests will blow up your system. A sensible workaround is to run it simply as an external microservice and call it asynchronously with a task queue. Therefore, your RAGAS service will consume as much traffic as it can handle at the same time, you’ll wait for your scores a little bit longer, but your users won’t wait for it with you.
Then there’s the asynchronous interface itself. Keeping a WebSocket open per chat session or per prompt can quickly exhaust your thread or port limits — particularly in a virtual container that shares network resources. Be aware that your scaling policy should not be based on CPU usage, which is usually quite low, but on the number of open connections in the load balancer.
Language Choice Revisited
You need Python for your libraries (like RAGAS), but you can split them into microservices and experiment with a JVM language like Java for the core app. Ports of libraries are often weaker than their Python originals (see LangChain versus LangChain4J), yet your system will scale far better under heavy I/O.
At the end it’s your choice to pick an easier implementation or a more robust application.
The Road Ahead
Have we eliminated all risks? Hardly. But you now have a solid foundation for building a production-grade assistant that scales. Next comes prompt engineering, data ingestion, tool selection, UI design, feedback collection, monitoring (beyond tracing) and more.
Building a chatbot prototype is easy. Building a production-ready AI assistant that can handle real users, scale reliably, and provide consistent value is an entirely different challenge. The gap between “it works on my machine” and “it serves thousands of users reliably” is filled with architectural decisions, performance optimizations, and operational considerations that are easy to overlook in the excitement of getting your first LLM call working.
Start with the prototype but plan for production from day one. Your users, your ops team and at the end your stakeholders – will thank you.
As AC/DC might put it: it’s a long way to the top if you want to… build an AI assistant.