The following is Part 1 of 3 from Addy Osmani’s original post “Context Engineering: Bringing Engineering Discipline to Parts.”
Context Engineering Tips:
To get the best results from an AI, you need to provide clear and specific context. The quality of the AI’s output directly depends on the quality of your input.
How to improve your AI prompts:
- Be precise: Vague requests lead to vague answers. The more specific you are, the better your results will be.
- Provide relevant code: Share the specific files, folders, or code snippets that are central to your request.
- Include design documents: Paste or attach sections from relevant design docs to give the AI the bigger picture.
- Share full error logs: For debugging, always provide the complete error message and any relevant logs or stack traces.
- Show database schemas: When working with databases, a screenshot of the schema helps the AI generate accurate code for data interaction.
- Use PR feedback: Comments from a pull request make for context-rich prompts.
- Give examples: Show an example of what you want the final output to look like.
- State your constraints: Clearly list any requirements, such as libraries to use, patterns to follow, or things to avoid.
Prompt engineering was about cleverly phrasing a question; context engineering is about constructing an entire information environment so the AI can solve the problem reliably.
“Prompt engineering” became a buzzword essentially meaning the skill of phrasing inputs to get better outputs. It taught us to “program in prose” with clever one-liners. But outside the AI community, many took prompt engineering to mean just typing fancy requests into a chatbot. The term never fully conveyed the real sophistication involved in using LLMs effectively.
As applications grew more complex, the limitations of focusing only on a single prompt became obvious. One analysis quipped: Prompt engineering walked so context engineering could run. In other words, a witty one-off prompt might have wowed us in demos, but building reliable, industrial-strength LLM systems demanded something more comprehensive.
This realization is why our field is coalescing around “context engineering” as a better descriptor for the craft of getting great results from AI. Context engineering means constructing the entire context window an LLM sees—not just a short instruction, but all the relevant background info, examples, and guidance needed for the task.
The phrase was popularized by developers like Shopify’s CEO Tobi Lütke and AI leader Andrej Karpathy in mid-2025.
“I really like the term ‘context engineering’ over prompt engineering,” wrote Tobi. “It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.” Karpathy emphatically agreed, noting that “people associate prompts with short instructions, whereas in every serious LLM application, context engineering is the delicate art and science of filling the context window with just the right information for each step.”
In other words, real-world LLM apps don’t succeed by luck or one-shot prompts—they succeed by carefully assembling context around the model’s queries.
The change in terminology reflects an evolution in approach. If prompt engineering was about coming up with a magical sentence, context engineering is about writing the full screenplay for the AI. It’s a structural shift: Prompt engineering ends once you craft a good prompt, whereas context engineering begins with designing whole systems that bring in memory, knowledge, tools, and data in an organized way.
As Karpathy explained, doing this well involves everything from clear task instructions and explanations, to providing few-shot examples, retrieved facts (RAG), possibly multimodal data, relevant tools, state history, and careful compacting of all that into a limited window. Too little context (or the wrong kind) and the model will lack the information to perform optimally; too much irrelevant context and you waste tokens or even degrade performance. The sweet spot is non-trivial to find. No wonder Karpathy calls it both a science and an art.
The term context engineering is catching on because it intuitively captures what we actually do when building LLM solutions. “Prompt” sounds like a single short query; “context” implies a richer information state we prepare for the AI.
Semantics aside, why does this shift matter? Because it marks a maturing of our mindset for AI development. We’ve learned that generative AI in production is less like casting a single magic spell and more like engineering an entire environment for the AI. A one-off prompt might get a cool demo, but for robust solutions you need to control what the model “knows” and “sees” at each step. It often means retrieving relevant documents, summarizing history, injecting structured data, or providing tools—whatever it takes so the model isn’t guessing in the dark. The result is we no longer think of prompts as one-off instructions we hope the AI can interpret. We think in terms of context pipelines: all the pieces of information and interaction that set the AI up for success.

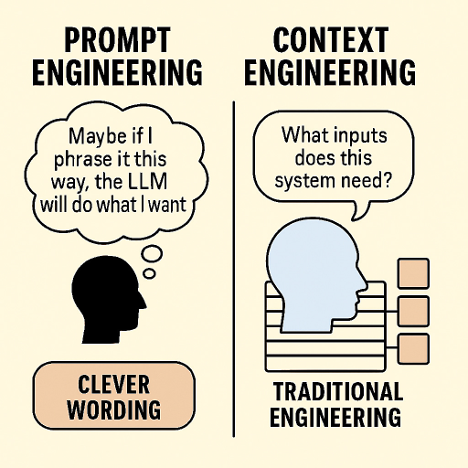
To illustrate, consider the difference in perspective. Prompt engineering was often an exercise in clever wording (“Maybe if I phrase it this way, the LLM will do what I want”). Context engineering, by contrast, feels more like traditional engineering: What inputs (data, examples, state) does this system need? How do I get those and feed them in? In what format? At what time? We’ve essentially gone from squeezing performance out of a single prompt to designing LLM-powered systems.
What Exactly Is Context Engineering?
Context engineering means dynamically giving an AI everything it needs to succeed—the instructions, data, examples, tools, and history—all packaged into the model’s input context at runtime.
A useful mental model (suggested by Andrej Karpathy and others) is to think of an LLM like a CPU, and its context window (the text input it sees at once) as the RAM or working memory. As an engineer, your job is akin to an operating system: load that working memory with just the right code and data for the task. In practice, this context can come from many sources: the user’s query, system instructions, retrieved knowledge from databases or documentation, outputs from other tools, and summaries of prior interactions. Context engineering is about orchestrating all these pieces into the prompt that the model ultimately sees. It’s not a static prompt but a dynamic assembly of information at runtime.

Let’s break down what this involves:
- It’s a system, not a one-off prompt. In a well-engineered setup, the final prompt the LLM sees might include several components: e.g., a role instruction written by the developer, plus the latest user query, plus relevant data fetched on the fly, plus perhaps a few examples of desired output format. All of that is woven together programmatically. For example, imagine a coding assistant AI that gets the query “How do I fix this authentication bug?” The system behind it might automatically search your codebase for related code, retrieve the relevant file snippets, and then construct a prompt like: “You are an expert coding assistant. The user is facing an authentication bug. Here are relevant code snippets: [code]. The user’s error message: [log]. Provide a fix.” Notice how that final prompt is built from multiple pieces. Context engineering is the logic that decides which pieces to pull in and how to join them. It’s akin to writing a function that prepares arguments for another function call—except here, the “arguments” are bits of context and the function is the LLM invocation.
- It’s dynamic and situation-specific. Unlike a single hard-coded prompt, context assembly happens per request. The system might include different info depending on the query or the conversation state. If it’s a multi-turn conversation, you might include a summary of the conversation so far, rather than the full transcript, to save space (and sanity). If the user’s question references some document (“What does the design spec say about X?”), the system might fetch that spec from a wiki and include the relevant excerpt. In short, context engineering logic responds to the current state—much like how a program’s behavior depends on input. This dynamic nature is crucial. You wouldn’t feed a translation model the exact same prompt for every sentence you translate; you’d feed it the new sentence each time. Similarly, in an AI agent, you’re constantly updating what context you give as the state evolves.
- It blends multiple types of content. LangChain describes context engineering as an umbrella that covers at least three facets of context: (1) Instructional context—the prompts or guidance we provide (including system role instructions and few-shot examples), (2) Knowledge context—domain information or facts we supply, often via retrieval from external sources, and (3) Tools context—information coming from the model’s environment via tools or API calls (e.g., results from a web search, database query, or code execution). A robust LLM application often needs all three: clear instructions about the task, relevant knowledge plugged in, and possibly the ability for the model to use tools and then incorporate the tool results back into its thinking. Context engineering is the discipline of managing all these streams of information and merging them coherently.
- Format and clarity matter. It’s not just what you include in the context, but how you present it. Communicating with an AI model has surprising parallels to communicating with a human: If you dump a huge blob of unstructured text, the model might get confused or miss the point, whereas a well-organized input will guide it. Part of context engineering is figuring out how to compress and structure information so the model grasps what’s important. This could mean summarizing long texts, using bullet points or headings to highlight key facts, or even formatting data as JSON or pseudo-code if that helps the model parse it. For instance, if you retrieved a document snippet, you might preface it with something like “Relevant documentation:” and put it in quotes, so the model knows it’s reference material. If you have an error log, you might show only the last 5 lines rather than 100 lines of stack trace. Effective context engineering often involves creative information design—making the input as digestible as possible for the LLM.
Above all, context engineering is about setting the AI up for success.
Remember, an LLM is powerful but not psychic—it can only base its answers on what’s in its input plus what it learned during training. If it fails or hallucinates, often the root cause is that we didn’t give it the right context, or we gave it poorly structured context. When an LLM “agent” misbehaves, usually “the appropriate context, instructions and tools have not been communicated to the model.” Garbage in, garbage out. Conversely, if you do supply all the relevant info and clear guidance, the model’s performance improves dramatically.
Feeding high-quality context: Practical tips
Now, concretely, how do we ensure we’re giving the AI everything it needs? Here are some pragmatic tips that I’ve found useful when building AI coding assistants and other LLM apps:
- Include relevant source code and data. If you’re asking an AI to work on code, provide the relevant code files or snippets. Don’t assume the model will recall a function from memory—show it the actual code. Similarly, for Q&A tasks include the pertinent facts or documents (via retrieval). Low context guarantees low-quality output. The model can’t answer what it hasn’t been given.
- Be precise in instructions. Clearly state what you want. If you need the answer in a certain format (JSON, specific style, etc.), mention that. If the AI is writing code, specify constraints like which libraries or patterns to use (or avoid). Ambiguity in your request can lead to meandering answers.
- Provide examples of the desired output. Few-shot examples are powerful. If you want a function documented in a certain style, show one or two examples of properly documented functions in the prompt. Modeling the output helps the LLM understand exactly what you’re looking for.
- Leverage external knowledge. If the task needs domain knowledge beyond the model’s training (e.g., company-specific details, API specs), retrieve that info and put it in the context. For instance, attach the relevant section of a design doc or a snippet of the API documentation. LLMs are far more accurate when they can cite facts from provided text rather than recalling from memory.
- Include error messages and logs when debugging. If asking the AI to fix a bug, show it the full error trace or log snippet. These often contain the critical clue needed. Similarly, include any test outputs if asking why a test failed.
- Maintain conversation history (smartly). In a chat scenario, feed back important bits of the conversation so far. Often you don’t need the entire history—a concise summary of key points or decisions can suffice and saves token space. This gives the model context of what’s already been discussed.
- Don’t shy away from metadata and structure. Sometimes telling the model why you’re giving a piece of context can help. For example: “Here is the user’s query.” or “Here are relevant database schemas:” as prefacing labels. Simple section headers like “User Input: … / Assistant Response: …” help the model parse multi-part prompts. Use formatting (markdown, bullet lists, numbered steps) to make the prompt logically clear.
Remember the golden rule: LLMs are powerful but they aren’t mind-readers. The quality of output is directly proportional to the quality and relevance of the context you provide. Too little context (or missing pieces) and the AI will fill gaps with guesses (often incorrect). Irrelevant or noisy context can be just as bad, leading the model down the wrong path. So our job as context engineers is to feed the model exactly what it needs and nothing it doesn’t.
AI tools are quickly moving beyond chat UX to sophisticated agent interactions. Our upcoming AI Codecon event, Coding for the Future Agentic World, will highlight how developers are already using agents to build innovative and effective AI-powered experiences. We hope you’ll join us on September 9 to explore the tools, workflows, and architectures defining the next era of programming. It’s free to attend.
Register now to save your seat.