The following article originally appeared on Medium and is being republished here with the author’s permission.
Open source has been evolving for half a century, but the last two decades have set the stage for what comes next. The 2000s were the “star stage”—when open source became mainstream, commercial, and visible. The 2010s decentralized it, breaking the hierarchy and making forking normal. Now, in the 2020s, it’s transforming again as generative AI enters the scene—as a participant.
This decade isn’t just faster. It’s a different kind of speed. AI is starting to write, refactor, and remix code and open source projects at a scale no human maintainer can match. GitHub isn’t just expanding; it’s mutating, filled with AI-generated derivatives of human work, on track to manage close to 1B repositories by the end of the decade.
If we want to understand what’s happening to open source now, it helps to look back at how it evolved. The story of open source isn’t a straight line—it’s a series of turning points. Each decade changed not just the technology but also the culture around it: from rebellion in the 1990s to recognition in the 2000s to decentralization in the 2010s. Those shifts built the foundation for what’s coming next—an era where code isn’t just written by developers but by the agents they are managing.
1990s: Setting the Stage
The late ’80s and early ’90s were defined by proprietary stacks—Windows, AIX, Solaris. By the mid-’90s, developers began to rebel. Open source wasn’t just an ideal; it was how the web got built. Most sites ran Apache on the frontend but relied on commercial engines such as Dynamo and Oracle on the backend. The first web was open at the edges and closed at the core.
In universities and research labs, the same pattern emerged. GNU tools like Emacs, GCC, and gdb were everywhere, but they ran on proprietary systems—SGI, Solaris, NeXT, AIX. Open source had taken root, even if the platforms weren’t open. Mike Loukides and Andy Oram’s Programming with GNU Software (1996) captured that world perfectly: a maze of UNIX variants where every system broke your scripts in a new way. Anyone who learned command-line syntax on AIX in the early ’90s still trips over it on macOS today.
That shift—Linux and FreeBSD meeting the web—set the foundation for the next decade of open infrastructure. Clearly, Tim Berners-Lee’s work at CERN was the pivotal event that defined the next century, but I think the most tactical win from the 1990s was Linux. Even though Linux didn’t become viable for large-scale use until 2.4 in the 2000s, it set the stage.
2000s: The Open Source Decade
The 2000s were when open source went mainstream. Companies that once sold closed systems started funding the foundations that challenged them—IBM, Sun, HP, Oracle, and even Microsoft. It wasn’t altruism; it was strategy. Open source had become a competitive weapon, and being a committer had become a form of social capital. The communities around Apache, Eclipse, and Mozilla weren’t just writing code; they built a sort of reputation game. “I’m a committer” could fund a startup or land you a job.

As open source gained momentum, visibility became its own form of power. Being a committer was social capital, and fame within the community created hierarchy. The movement that had started as a rebellion against proprietary control began to build its own “high places.” Foundations became stages; conferences became politics. The centralized nature of CVS and Subversion reinforced this hierarchy—control over a single master repository meant control over the project itself. Forking wasn’t seen as collaboration; it was defiance. And so, even in a movement devoted to openness, authority began to concentrate.
By the end of the decade, open source had recreated the very structures it once tried to dismantle and there were power struggles around forking and control—until Git arrived and quietly made forking not just normal but encouraged.
In 2006, Linus Torvalds quietly dropped something that would reshape it all: Git. It was controversial, messy, and deeply decentralized—the right tool at the right time.
2010s: The Great Decentralization
The 2010s decentralized everything. Git unseated Subversion and CVS, making forking normal. GitHub turned version control into a social network, and suddenly open source wasn’t a handful of central projects—it was thousands of competing experiments. Git made a fork cheap and local: Anyone could branch off instantly, hack in isolation, and later decide whether to merge back. That one idea changed the psychology of collaboration. Experimentation became normal, not subversive.
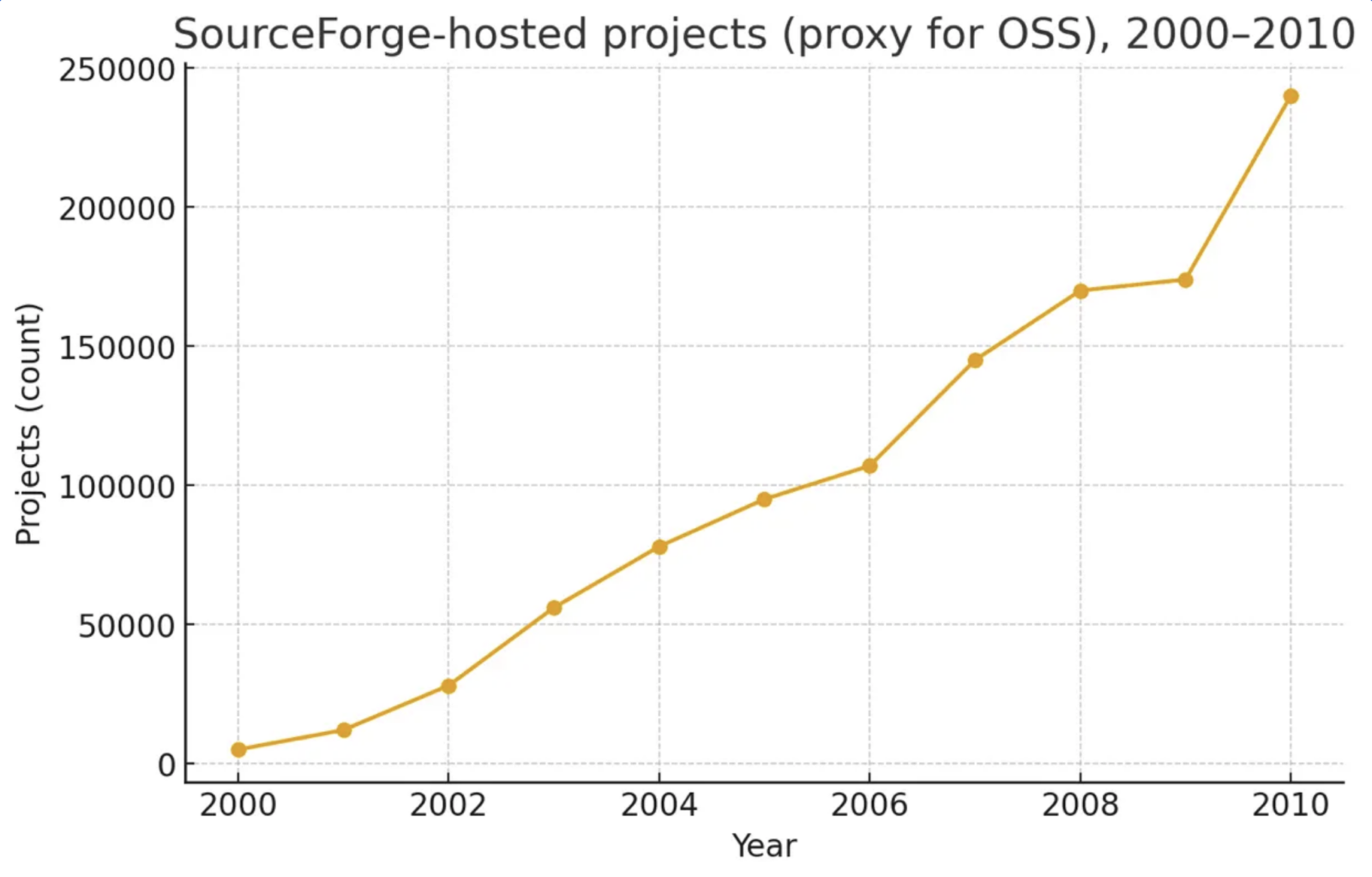
The effect was explosive. SourceForge, home to the CVS/SVN era, hosted about 240,000 projects by 2010. Ten years later, GitHub counted roughly 190 million repositories. Even if half were toy projects, that’s a two-to-three-order-of-magnitude jump in project creation velocity—roughly one new repository every few seconds by the late 2010s. Git didn’t just speed up commits; it changed how open source worked.
But the same friction that disappeared also removed filters. Because Git made experimentation effortless, “throwaway projects” became viable—half-finished frameworks, prototypes, and personal experiments living side by side with production-grade code. By mid-decade, open source had entered its Cambrian phase: While the 2000s gave us five or six credible frontend frameworks, the 2010s produced 50 or 60. Git didn’t just decentralize code—it decentralized attention.

2020s: What Will We Call This Decade?
Now that we’re halfway through the 2020s, something new is happening. Generative AI has slipped quietly into the workflow, reshaping open source once again—not by killing it but by making forking even easier. It also forms one of the main training inputs for the output it generates.
Go back two decades to the 2000s, if a library didn’t do what you needed, you joined the mailing list, earned trust, and maybe became a committer. That was slow, political, and occasionally productive. But for you or the companies you work for to be able to influence a project and commit code, we’re talking months or years of investment.
Today, if a project is 90 percent right, you fork it, describe the fix to an AI, and you move on 5 minutes later. No review queues. No debates about brace styles. The pull-request culture that once defined open source starts to feel optional because you aren’t investing any time in it to begin with.
In fact, you might not even be aware that you forked and patched something. One of the 10 agents you launched in parallel to reimplement an API might have forked a library, patched it for your specific use case, and published it to your private GitHub npm repository while you were at lunch. And you might not even be paying attention to those details.
Trend prediction: We’re going to have a nickname for developers who use GenAI and are unable to read the code it generated very soon because that’s happening.
Is Open Source Done?
No. But it’s already changing. The big projects will continue—React, Next.js, and DuckDB will keep growing because AI models already prefer them. And I do think there are still communities or developers who want to collaborate with other humans.
But there is a surge of AI-generated open source contributions and projects that will start to affect the ecosystem. Smaller, more focused libraries will start to see more forks. That’s my prediction, and it might get to the point where it doesn’t make much sense anymore to track them.
Instead of half a dozen stable frameworks per category, we’ll see hundreds of small, AI-tuned frameworks and forks, each solving one developer’s problem perfectly and then fading away. The social glue that once bound open source—mentorship, debate, shared maintenance—gets thinner. Collaboration gives way to radical personalization. And I don’t know if that’s such a bad thing.
The Fork-It-and-Forget Decade
This is shaping up to be the “fork-it-and-forget” decade. Developers—and the agents they run—are moving at a new kind of velocity: forking, patching, and moving on. GitHub reports more than 420 million repositories as of early 2023, and it’s on pace to hit a billion by 2030.
We tore down the “high places” that defined the 2000s and replaced them with the frictionless innovation of the 2010s. Now the question is whether we’ll even recognize open source by the end of this decade. I still pay attention to the libraries I’m pulling in, but most developers using tools like Cursor to write complex code probably don’t—and maybe don’t need to. The agent already forked it and moved on.
Maybe that’s the new freedom: to fork, to forget, and to let the machines remember for us.