Most multi-agent AI systems fail expensively before they fail quietly.
The pattern is familiar to anyone who’s debugged one: Agent A completes a subtask and moves on. Agent B, with no visibility into A’s work, reexecutes the same operation with slightly different parameters. Agent C receives inconsistent results from both and confabulates a reconciliation. The system produces output—but the output costs three times what it should and contains errors that propagate through every downstream task.
Teams building these systems tend to focus on agent communication: better prompts, clearer delegation, more sophisticated message-passing. But communication isn’t what’s breaking. The agents exchange messages fine. What they can’t do is maintain a shared understanding of what’s already happened, what’s currently true, and what decisions have already been made.
In production, memory—not messaging—determines whether a multi-agent system behaves like a coordinated team or an expensive collision of independent processes.
Multi-agent systems fail because they can’t share state
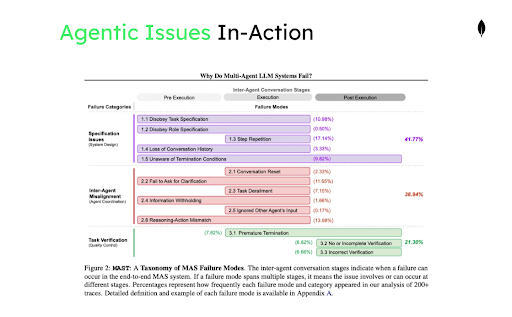
The evidence: 36% of failures are misalignment
Cemri et al. published the most systematic analysis of multi-agent failure to date. Their MAST taxonomy, built from over 1,600 annotated execution traces across frameworks like AutoGen, CrewAI, and LangGraph, identifies 14 distinct failure modes. The failures cluster into three categories: system design issues, interagent misalignment, and task verification breakdowns.

The number that matters: Interagent misalignment accounts for 36.9% of all failures. Agents don’t fail because they can’t reason. They fail because they operate on inconsistent views of shared state. One agent’s completed work doesn’t register in another agent’s context. Assumptions that were valid at step 3 become invalid by step 7, but no mechanism propagates the update. The team diverges.
What makes this structural rather than incidental is that message-passing architectures have no built-in answer to the question: “What does this agent know about what other agents have done?” Each agent maintains its own context. Synchronization happens through explicit messages, which means anything not explicitly communicated is invisible. In complex workflows, the set of things that need synchronization grows faster than any team can anticipate.
The origin: Decomposition without shared memory
Most multi-agent systems aren’t designed from first principles. They emerge from single-agent prototypes that hit scaling limits.
The starting point is usually one capable LLM handling one workflow. For early prototypes, this works well enough. But production requirements expand: more tools, more domain knowledge, longer workflows, concurrent users. The single agent’s prompt becomes unwieldy. Context management consumes more engineering time than feature development. The system becomes brittle in ways that are hard to diagnose.
The natural response is decomposition. Sydney Runkle’s guide on choosing the right multi-agent architecture captures the inflection point: Multi-agent systems become necessary when context management breaks down and when distributed development requires clear ownership boundaries. Splitting a monolithic agent into specialized subagents makes sense from a software engineering perspective.

The problem is what teams typically build after the split: multiple agents running the same base model, differentiated only by system prompts, coordinating through message queues or shared files. The architecture looks like a team but behaves like a slow, redundant, expensive single agent with extra coordination overhead.
This happens because the decomposition addresses prompt complexity but not state management. Each subagent still maintains its own context independently. The coordination layer handles message delivery but not shared truth. The system has more agents but no better memory.
The stakes: Agents are becoming enterprise infrastructure
The stakes here extend beyond individual system reliability. Multi-agent architectures are becoming the default pattern for enterprise AI deployment.
CMU’s AgentCompany benchmark frames where this is heading: agents operating as persistent coworkers inside organizational workflows, handling projects that span days or weeks, coordinating across team boundaries, maintaining institutional context that outlasts individual sessions. The benchmark evaluates agents not on isolated tasks but on realistic workplace scenarios requiring sustained collaboration.
This trajectory means the memory problem compounds. A system that loses state between tool calls is annoying. A system that loses state between work sessions—or between team members—breaks the core value proposition of agent-based automation. The question shifts from “can agents complete tasks” to “can agent teams maintain coherent operations over time.”
Context engineering doesn’t solve team coordination
Single-agent success doesn’t transfer
The last two years produced genuine progress on single-agent reliability, most of it under the banner of context engineering.
Phil Schmid’s framing captures the discipline: Context engineering means structuring what enters the context window, managing retrieval timing, and ensuring the right information surfaces at the right moment. This moved agent development from “write a good prompt” to “design an information architecture.” The results showed in production stability.

Manus, one of the few production agent systems with publicly documented operational data, demonstrates both the success and the limits. Their agents average 50 tool calls per task with 100:1 input-to-output token ratios. Context engineering made this viable—but context engineering assumes you control one context window.
Multi-agent systems break that assumption. Context must now be shared across agents, updated as execution proceeds, scoped appropriately (some agents need information others shouldn’t access), and kept consistent across parallel execution paths. The complexity doesn’t add linearly. Each agent’s context becomes a potential source of divergence from every other agent’s context, and the coordination overhead grows with the square of the team size.
Context degradation becomes contagious
The ways context fails are well-characterized for single agents. Drew Breunig’s taxonomy identifies four modes: overload (too much information), distraction (irrelevant information weighted equally with relevant), contamination (incorrect information mixed with correct), and drift (gradual degradation over extended operation). Good context engineering mitigates all of these through retrieval design and prompt structure.

Multi-agent systems make each failure mode contagious.
Chroma’s research on context rot provides the empirical mechanism. Their evaluation of 18 models—including GPT-4.1, Claude 4, and Gemini 2.5—shows performance degrading nonuniformly with context length, even on tasks as simple as text replication. The degradation accelerates when distractors are present and when the semantic similarity between query and target decreases.

In a single-agent system, context rot degrades that agent’s outputs. In a multi-agent system, Agent A’s degraded output enters Agent B’s context as ground truth. Agent B’s conclusions, now built on a shaky foundation, propagate to Agent C. Each hop amplifies the original error. By the time the workflow completes, the final output may bear little relationship to the actual state of the world—and debugging requires tracing corruption through multiple agents’ decision chains.
More context makes things worse
When coordination problems emerge, the instinct is often to give agents more context. Replay the full transcript so everyone knows what happened. Implement retrieval so agents can access historical state. Extend context windows to fit more information.

Each approach introduces its own failure modes.
Transcript replay creates unbounded prompt growth with persistent error exposure. Every mistake made early in execution remains in context, available to influence every subsequent decision. Models don’t automatically discount old information that’s been superseded by newer updates.
Retrieval surfaces content based on similarity, which doesn’t necessarily correlate with decision relevance. A retrieval system might surface a semantically similar memory from a different task context, an outdated state that’s since been updated, or content injected through prompt manipulation. The agent has no way to distinguish authoritative current state from plausibly related historical noise.

Want Radar delivered straight to your inbox? Join us on Substack. Sign up here.
Bousetouane’s work on bounded memory control addresses this directly. The proposed Agent Cognitive Compressor maintains bounded internal state with explicit separation between what an agent can recall and what it commits to shared memory. The architecture prevents drift by making memory updates deliberate rather than automatic. The core insight: Reliability requires controlling what agents remember, not maximizing how much they can access.
The economics are unsustainable
Beyond reliability, the economics of uncoordinated multi-agent systems are punishing.
Return to the Manus operational data: 50 tool calls per task, 100:1 input-to-output ratios. At current pricing—context tokens running $0.30 to $3.00 per million across major providers—inefficient memory management makes many workflows economically unviable before they become technically unviable.
Anthropic’s documentation on its multi-agent research system quantifies the multiplier effect. Single agents use roughly 4x the tokens of equivalent chat interactions. Multi-agent systems use roughly 15x tokens. The gap reflects coordination overhead: agents reretrieving information other agents already fetched, reexplaining context that should exist as shared state, and revalidating assumptions that could be read from common memory.
Memory engineering addresses costs directly. Shared memory eliminates redundant retrieval. Bounded context prevents payment for irrelevant history. Clear coordination boundaries prevent duplicated work. The economics of what to forget become as important as the economics of what to remember.
Memory engineering provides the missing infrastructure
Why memory is infrastructure, not a feature
Memory engineering isn’t a feature to add after the agent architecture is working. It’s infrastructure that makes coherent agent architectures possible.
The parallel to databases is direct. Before databases, multiuser applications required custom solutions for shared state, consistency guarantees, and concurrent access. Each project reinvented these primitives. Databases extracted the common requirements into infrastructure: shared truth across users, atomic updates that complete entirely or not at all, coordination that scales to thousands of concurrent operations without corruption.

Multi-agent systems need equivalent infrastructure for agent coordination. Persistent memory that survives sessions and failures. Consistent state that all agents can trust. Atomic updates that prevent partial writes from corrupting shared truth. The primitives are different—documents rather than rows, vector similarity rather than joins—but the role in the architecture is the same.
The five pillars of multi-agent memory
Production agent teams require five capabilities. Each addresses a distinct aspect of how agents maintain shared understanding over time.
Pillar 1: Memory taxonomy
Memory taxonomy defines what kinds of memory the system maintains. Not all memories serve the same function, and treating them uniformly creates problems. Working memory holds transient state during task execution—the current step, intermediate results, active constraints. It needs fast access and can be discarded when the task completes. Episodic memory captures what happened—task histories, interaction logs, decision traces. It supports debugging and learning from past executions. Semantic memory stores durable knowledge—facts, relationships, domain models that persist across sessions and apply across tasks. Procedural memory encodes how to do things—learned workflows, tool usage patterns, successful strategies that agents can reuse. Shared memory spans agents, providing the common ground that enables coordination.

This taxonomy has grounding in cognitive science. Bousetouane draws on Complementary Learning Systems theory, which posits two distinct modes of learning: rapid encoding of specific experiences versus gradual extraction of structured knowledge. The human brain doesn’t maintain perfect transcripts of past events—it operates under capacity constraints, using compression and selective attention to keep only what’s relevant to the current task. Agents benefit from the same principle. Rather than accumulating raw interaction history, effective memory architectures distill experience into compact, task-relevant representations that can actually inform decisions.
The taxonomy matters because each memory type has different retention requirements, different retrieval patterns, and different consistency needs. Working memory can tolerate eventual consistency because it’s scoped to one agent’s execution. Shared memory requires stronger guarantees because multiple agents depend on it. Systems that don’t distinguish memory types end up either overpersisting transient state (wasting storage and polluting retrieval) or underpersisting durable knowledge (forcing agents to relearn what they should already know).
Pillar 2: Persistence
Persistence determines what survives and for how long. Ephemeral memory lost when agents terminate is insufficient for workflows spanning hours or days—but persisting everything forever creates its own problems. The critical gap in most current approaches, as Bousetouane observes, is that they treat text artifacts as the primary carrier of state without explicit rules governing memory lifecycle. Which memories should become permanent record? Which need revision as context evolves? Which should be actively forgotten? Without answers to these questions, systems accumulate noise alongside signal. Effective persistence requires explicit lifecycle policies: Working memory might live for the duration of a task; episodic memory for weeks or months; and semantic memory indefinitely. Recovery semantics matter too. When an agent fails midtask, what state can be reconstructed? What’s lost? The persistence architecture must handle both planned retention and unplanned recovery.
Pillar 3: Retrieval
Retrieval governs how agents access relevant memory without drowning in noise. Agent memory retrieval differs from document retrieval in several ways. Recency often matters—recent memories typically outweigh older ones for ongoing tasks. Relevance is contextual—the same memory might be critical for one task and distracting for another. Scope varies by memory type—working memory retrieval is narrow and fast, semantic memory retrieval is broader and can tolerate more latency. Standard RAG pipelines treat all content uniformly and optimize for semantic similarity alone. Agent memory systems need retrieval strategies that account for memory type, recency, task context, and agent role simultaneously.
Pillar 4: Coordination
Coordination defines the sharing topology. Which memories are visible to which agents? What can each agent read versus write? How do memory scopes nest or overlap? Without explicit coordination boundaries, teams either overshare—every agent sees everything, creating noise and contamination risk—or undershare—agents operate in isolation, duplicating work and diverging on shared tasks. The coordination model must match the agent team’s structure. A supervisor-worker hierarchy needs different memory visibility than a peer collaboration. A pipeline of sequential agents needs different sharing than agents working in parallel on subtasks.
Pillar 5: Consistency
Consistency handles what happens when memory updates collide. When Agent A and Agent B simultaneously update the same shared state with incompatible values, the system needs a policy. Optimistic concurrency with merge strategies works for many cases—especially when conflicts are rare and resolvable. Some conflicts require escalation to a supervisor agent or human operator. Some domains need strict serialization where only one agent can update certain memories at a time. Silent last-write-wins is almost never correct—it corrupts shared truth without leaving evidence that corruption occurred. The consistency model must also handle ordering: When Agent B reads a memory that Agent A recently updated, does B see the update? The answer depends on the consistency guarantees the system provides, and different memory types may warrant different guarantees.
Han et al.’s survey of multi-agent systems emphasizes that these represent active research problems. The gap between what production systems need and what current frameworks provide remains substantial. Most orchestration frameworks handle message passing well but treat memory as an afterthought—a vector store bolted on for retrieval, with no coherent model for the other four pillars.

Database primitives that enable the pillars
Implementing memory engineering requires a storage layer that can serve as unified operational database, knowledge store, and memory system simultaneously. The requirements cut across traditional database categories: You need document flexibility for evolving memory schemas, vector search for semantic retrieval, full-text search for precise lookups, and transactional consistency for shared state.
MongoDB provides these primitives in a single platform, which is why it appears across so many agent memory implementations—whether teams build custom solutions or integrate through frameworks and memory providers.
Document flexibility matters because memory schemas evolve. A memory unit isn’t a flat string—it’s structured content with metadata, timestamps, source attribution, confidence scores, and associative links to related memories. Teams discover what context agents actually need through iteration. Document databases accommodate this evolution without schema migrations blocking development.
Hybrid retrieval addresses the access pattern problem. Agent memory queries rarely fit a single retrieval mode: A typical query needs memories semantically similar to the current task and created within the last hour and tagged with a specific workflow ID and not marked as superseded. MongoDB Atlas Vector Search combines vector similarity, full-text search, and filtered queries in single operations, avoiding the complexity of stitching together separate retrieval systems.

Atomic operations provide the consistency primitives that coordination requires. When an agent updates task status from pending to complete, the update succeeds entirely or fails entirely. Other agents querying task status never observe partial updates. This is standard MongoDB functionality—findAndModify, conditional updates, multidocument transactions—but it’s infrastructure that simpler storage backends lack.
Change streams enable event-driven architectures. Applications can subscribe to database changes and react when relevant state updates, rather than polling. This becomes a building block for memory systems that need to propagate updates across agents.
Teams implement memory engineering on MongoDB through three paths. Some build directly on the database, using the document model and search capabilities to create custom memory architectures matched to their specific coordination patterns. Others work through orchestration frameworks—LangChain, LlamaIndex, CrewAI—that provide MongoDB integrations for their memory abstractions. Still others adopt dedicated memory providers like Mem0 or Agno, which handle the memory logic while using MongoDB as the underlying storage layer.
The flexibility matters because memory engineering isn’t a single pattern. Different agent architectures need different memory topologies, different consistency guarantees, different retrieval strategies. A database that prescribes one approach would fit some use cases and break others. MongoDB provides primitives; teams compose them into the memory systems their agents require.
Shared memory enables heterogeneous agent teams
Homogeneous systems can be replaced by single agents
The deeper payoff of memory engineering is enabling agent architectures that wouldn’t otherwise be viable.
Xu et al. observe that many deployed multi-agent systems are so homogeneous—same base model everywhere, agents differentiated only by prompts—that a single model can simulate the entire workflow with equivalent results and lower overhead. Their OneFlow optimization demonstrates this by reusing KV cache across simulated “agents” within a single execution, eliminating coordination costs while preserving workflow structure.
The implication: If a single agent can replace your multi-agent system, you haven’t built a team. You’ve built an expensive way to run one model.
Small models need external memory to coordinate
Genuine multi-agent value comes from heterogeneity. Different models with different capabilities operating at different price points for different subtasks. Belcak et al. make the case that most work agents do in production isn’t complex reasoning—it’s routine execution of well-defined operations. Parsing a response, formatting an output, invoking a tool with specific parameters. These tasks don’t require frontier model capabilities, and the cost difference is dramatic: Their analysis puts the gap at 10x–30x between serving a 7B parameter model versus a 70–175B parameter model when you factor in latency, energy, and compute. Large models should be reserved for the genuinely hard problems, not deployed uniformly across every step.
Belcak et al. also highlight an operational advantage: Smaller models can be retrained and adapted much faster. When an agent needs new capabilities or exhibits problematic behaviors, the turnaround for fine-tuning a 7B model is measured in hours, not days. This connects to memory engineering because fine-tuning represents an alternative to retrieval—you can bake procedural knowledge directly into model weights rather than surfacing it from external storage at runtime. The choice between the procedural memory pillar and model specialization becomes a design decision rather than a constraint.
This architecture—small models by default, large models for hard problems—depends on shared memory. Small models can’t maintain the context required for coordination on their own. They rely on external memory to participate in larger workflows. Memory engineering makes heterogeneous teams viable; without it, every agent must be large enough to maintain full context independently, which defeats the cost optimization that motivates heterogeneity in the first place.
Building the foundation
Multi-agent systems fail for structural reasons: context degrades across agents, errors propagate through shared interactions, costs multiply with redundant operations, and state diverges when nothing enforces consistency. These problems don’t resolve with better prompts or more sophisticated orchestration. They require infrastructure.
Memory engineering provides that infrastructure through a coherent taxonomy of memory types, persistence with explicit lifecycle rules, retrieval tuned to agent access patterns, coordination that defines clear sharing boundaries, and consistency that maintains shared truth under concurrent updates.
The organizations that make multi-agent systems work in production won’t be distinguished by agent count or model capability. They’ll be the ones that invested in the memory layer that transforms independent agents into coordinated teams.
References
Anthropic. “Building a Multi-Agent Research System.” 2025. https://www.anthropic.com/engineering/multi-agent-research-system
Belcak, Peter, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, and Pavlo Molchanov. “Small Language Models are the Future of Agentic AI.” arXiv:2506.02153 (2025). https://arxiv.org/abs/2506.02153
Bousetouane, Fouad. “AI Agents Need Memory Control Over More Context.” arXiv:2601.11653 (2026). https://arxiv.org/abs/2601.11653
Breunig, Dan. “How Contexts Fail—and How to Fix Them.” June 22, 2025. https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
Carnegie Mellon University. “AgentCompany: Building Agent Teams for the Future of Work.” 2025. https://www.cs.cmu.edu/news/2025/agent-company
Cemri, Mert, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. “Why Do Multi-Agent LLM Systems Fail?” arXiv:2503.13657 (2025). https://arxiv.org/abs/2503.13657
Chroma Research. “Context Rot: How Increasing Context Length Degrades Model Performance.” 2025. https://research.trychroma.com/context-rot
Han, Shanshan, Qifan Zhang, Yuhang Yao, Weizhao Jin, and Zhaozhuo Xu. “LLM Multi-Agent Systems: Challenges and Open Problems.” arXiv:2402.03578 (2024). https://arxiv.org/abs/2402.03578
LangChain Blog (Sydney Runkle). “Choosing the Right Multi-Agent Architecture.” January 14, 2026. https://www.blog.langchain.com/choosing-the-right-multi-agent-architecture/
Manus AI. “Context Engineering for AI Agents: Lessons from Building Manus.” 2025. https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
Schmid, Philipp. “Context Engineering.” 2025. https://www.philschmid.de/context-engineeringXu, Jiawei, Arief Koesdwiady, Sisong Bei, Yan Han, Baixiang Huang, Dakuo Wang, Yutong Chen, Zheshen Wang, Peihao Wang, Pan Li, and Ying Ding. “Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline.” arXiv:2601.12307 (2026). https://arxiv.org/abs/2601.12307
| To explore memory engineering further, start experimenting with memory architectures using MongoDB Atlas or review our detailed tutorials available at AI Learning Hub. |